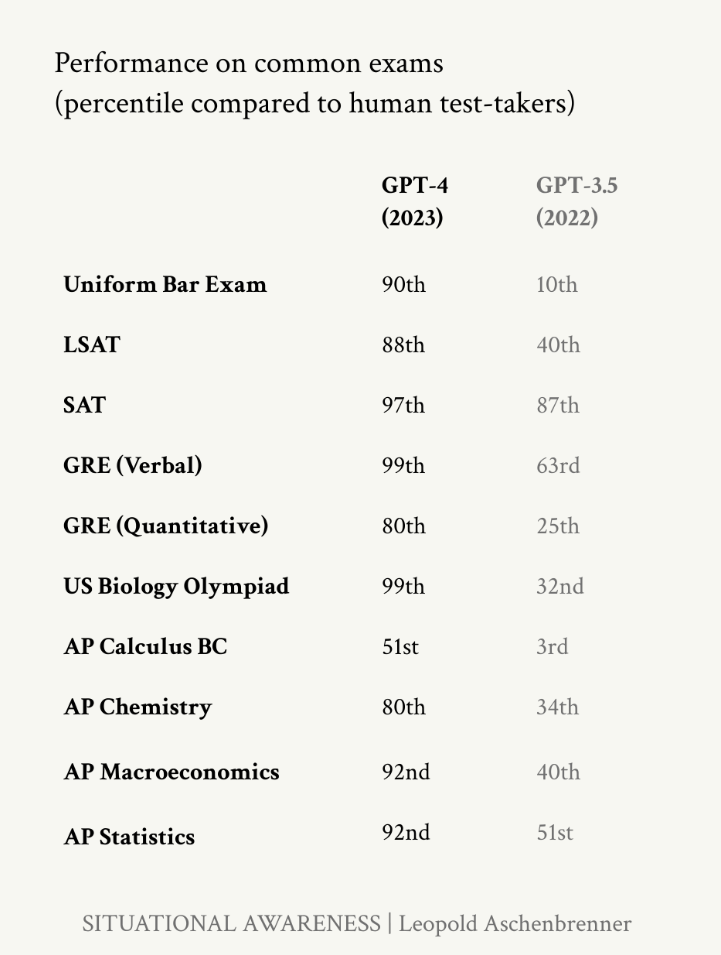
From GPT-4 to AGI

Article Description
This article makes the case that a leap to AGI by 2027 is possible, predicting and explaining that we should see another leap equivalent to the leap from GPT2 to GPT4 over the next 3 years.
Counting the Efficiency Increase
The author has a theory, that the progress in AI will come from a combination of:
- How much more powerful the computers are (compute).
- How much smarter the algorithms are getting (algorithmic efficiencies), which makes the computers feel even more powerful (we call this "effective compute").
- How fixing small issues can make AI even better (unhobbling gains).
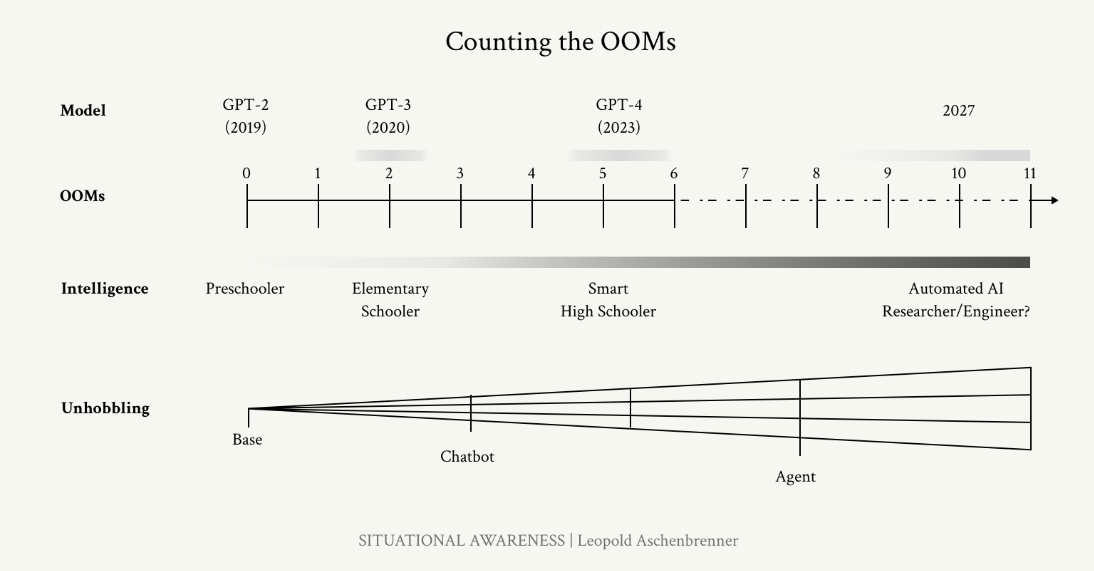
They sum all of this up into a framework called OOM (Order of Magnitude) where gains happen in multiples of 10x.
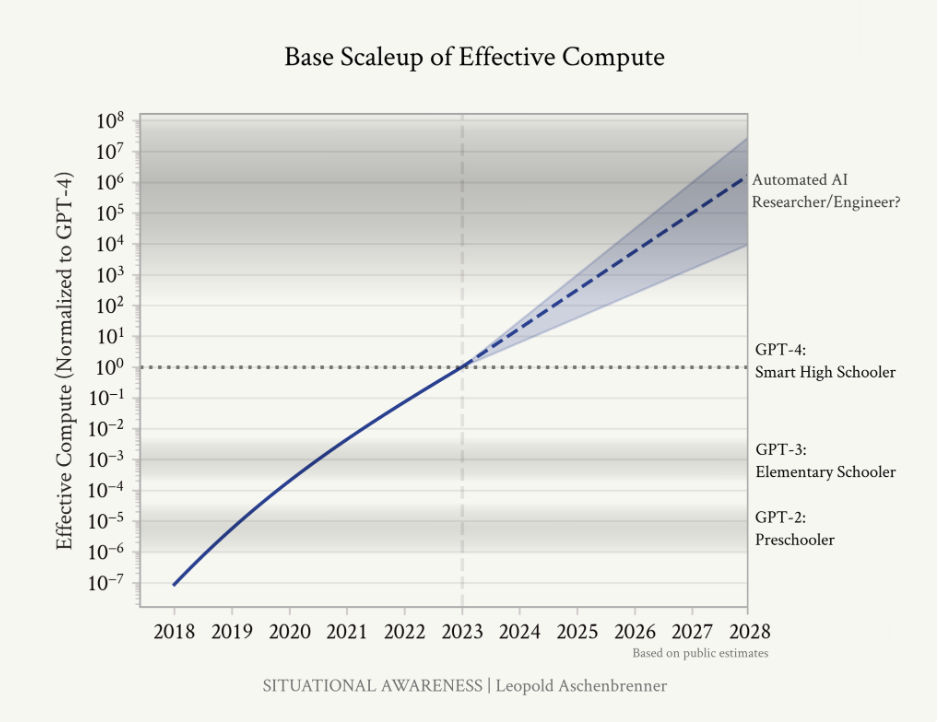
So they expect an increase in 100,000 in effective compute scaleup over the next 4 years.
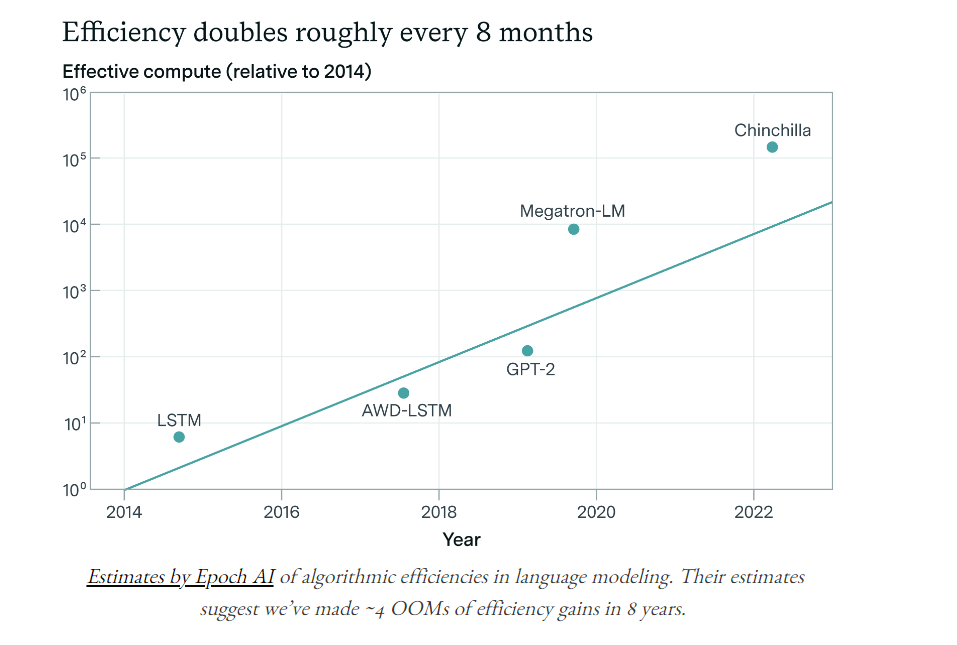
Look at the chart below for the improvment tha thas been made in a single year.

Follow the OOM to see a glimpse of the future
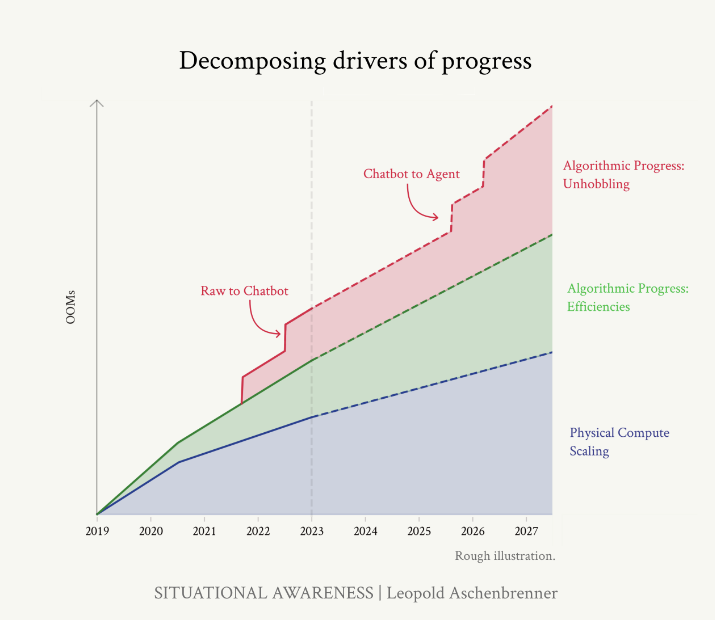
We can break down the progress from GPT-2 to GPT-4 into three big improvements:
- Compute: We're using much bigger and more powerful computers to train these AI models.
- Algorithmic efficiencies: The algorithms are getting better and smarter, making the computers seem even more powerful. We can measure this as growing "effective compute."
- Unhobbling gains: AI models have lots of potential, but they are held back by simple issues. By making small fixes like using human feedback, step-by-step thinking, and adding helpful tools, we can unlock a lot of hidden abilities and make the AI much more useful.
The data wall and how to smash through it
But maybe there is a way to be more efficient with the data we have.
What a modern AI model (LLM) does during training is like skimming through a textbook really fast without much thinking.
When we read a math textbook, we do it slowly, think about it, discuss it with friends, and try practice problems until we understand. We wouldn't learn much if we just skimmed through it like the AI models do.
But, there are ways to help AI models learn better by making them do what we do: think about the material, discuss it, and keep trying problems until they get it. This is what synthetic data, self-play, and reinforcement learning approaches aim to achieve.
A counter argument to stalled progress
AlphaGo, the first AI to beat world champions at Go, is a great example.
- Step 1: AlphaGo learned by watching expert human Go games. This gave it a basic understanding.
- Step 2: AlphaGo played millions of games against itself. This made it super good at Go, leading to moves like the famous move 37 against Lee Sedol, which was brilliant and unexpected. This self-play method allowed AlphaGo to explore new strategies and refine its skills beyond human capabilities. It shows how AI can advance rapidly by learning from its own experiences, potentially leading to breakthroughs in other fields as well.
Unhobbling
Finally, let's talk about "unhobbling" - making AI models work better by removing simple limitations.
Imagine if you had to solve a hard math problem instantly, without working it out step-by-step. It would be really hard, right? That’s how we used to make AI solve math problems. But we figured out a better way: letting AI work through problems step-by-step, just like we do. This small change, called "Chain-of-Thought" prompting, made AI much better at solving difficult problems.
We've made big improvements in "unhobbling" AI models over the past few years:
-
Reinforcement Learning from Human Feedback (RLHF): This technique helps AI learn from human feedback, making it more useful and practical. It's not just about censoring bad words; it helps the AI understand and answer questions better. For example, a small AI model trained with RLHF can perform as well as a much larger model without it.
-
Chain of Thought (CoT): This technique lets AI think through problems step-by-step. It’s like giving the AI a scratchpad to work out math and reasoning problems, making it much more effective.
-
Scaffolding: This involves using multiple AI models together. One model plans how to solve a problem, another proposes solutions, and another critiques them. This teamwork approach can make even smaller models perform better than larger ones working alone.
-
Tools: Imagine if humans couldn't use calculators or computers. Similarly, giving AI models tools like web browsers or code execution capabilities helps them perform better. ChatGPT can now do things like browse the web and run code.
-
Context Length: Early models could only remember a small amount of information at once. Now, models can remember much more (from 2k tokens to over 1 million tokens). This helps them understand and work on bigger tasks, like understanding a large codebase or writing a long document.
-
Posttraining Improvements: Even after training, AI models can continue to improve. For example, the current GPT-4 has gotten much better at reasoning and other tasks compared to when it was first released.
By removing these limitations, we've made AI models much more powerful and useful.