How to Improve AI Embedding Retrieval

Table of Contents
Subscribe to get access to these posts, and every post

Goals
- Understand how to better improve Retrieval Augmented Generation Applications
Key takeaways
Pitfalls of Retrieval
- Distractors are embedding chunks returned that isn't necessarily related
- These can occur because simple vector retrieval does not have any context other the mapping the query to a vector space and finding its nearest neighbours
- Distractors heavily impact the LLM's reason—perhaps
- These suboptiomal responses are also difficult to debug
Improving queries
- Query expansions are the simplest way to improve query results
- Expansion with generated answers is a appraoch in which we use the LLM to directly imagine answers based on the query and then use that result as the vector query for the real answers
- You basically ask the model to hallucinate to get a helpful input prompt for the vector query
- Expansion with multiple queries in which we use the LLM to generate similar queries to be fed into the vector search, the queries generated are handled as individual vector queries each. So there is a required extra step once you recieve all the real results from the database to de-duplicate the repsonses.
- The system prompts for these are very important, the arxiv paper examples are the best starting point but you must experiment
Cross-encoder Re-ranking
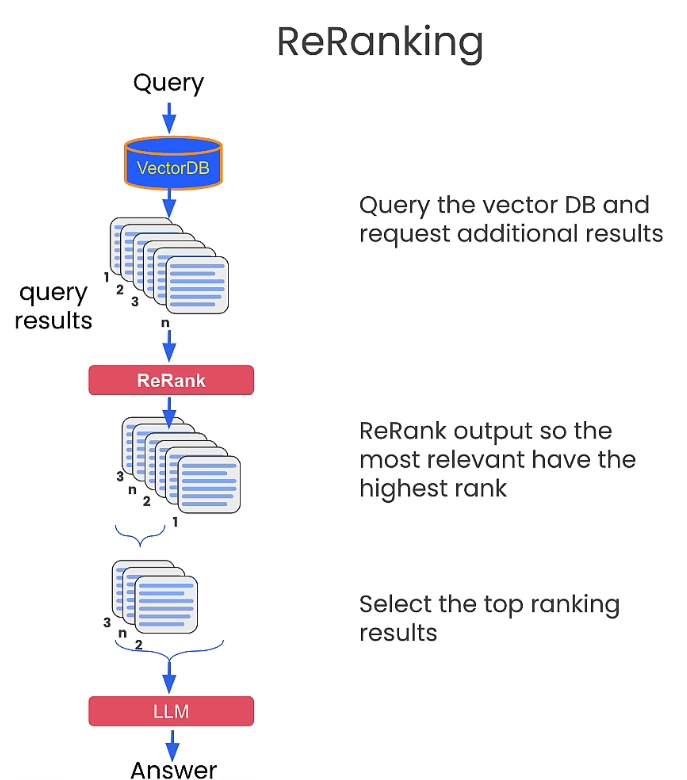
- Re-ranking is a way to order results and score them to a particular query
- One use of re-ranking is to get more information out of the long tail of results
- You do need to ask for more results from the vector query for this to be useful
- This allows for returned results to be more than just what is the closest in the vector space
- You can combine re-ranking with multiple query expansions to get the most relevant responses from the long tailed responses
Embedding Adapters
- The adapters are a way to alter the embedding directly to produce better results
- This requires a lightweight model
- This uses feedback from users
- The user feedback is the dataset that will train the lightweight model
- You can use LLMs to supplement and create the initial training data for this model
- This uses cosine similarity, which basically reduces vectors to direction vectors of 1 or -1
- Cosine similarity uses MSE loss combined with the embeddings
- It's the size of a single linear layer of a nueral network meaning this can be trained increadibly faster
- So fast it could be possible for individuals / companies / etc to have their own adapter specific to their feedback
- This embedding adapter is essential stretching or squeezing the space of the embeddings to the dimensions that are most relevant to their query
- Instead of a simple Cosine similarity model you could train a neural network to do this to allow for more option space

Random Notes
- chunk overlap is a powerful hyperparameter to test
- Recursively character splitting for chunking isn't sufficient, some chunk will be large tthan token context windows, meaning some text will be ignored, in this case use a sentence tokeniser to chunk further
- Vectors can be projected to 2D space using umap
- 2D representations of vectors don't share the exact multi dimensionality of the vector but offer a better visual
- You can fine tune your own embedding model using similar data from the embedding adapters
- You can fine tune the LLM to expect retrieved results and reason with them (RAFT, RA-DIT)
- There is a lot of experimentation currently around using deep models and transformers to improve chunking